浸大兩款AI模型|AI生成動作及角色 具備Sora與CG優勢
原文刊於信報財經新聞「EJ Tech 創科鬥室」
美企OpenAI發布短片生成模型Sora後,隨即令科技及影視界驚艷。本地擁有電影學院的香港浸會大學,亦於香港國際影視展發布最新研究成果,重點介紹功能跟Sora類似的動作生成模型MotionGPT,以及虛擬化身模型BuVatar。領導研發的浸大計算機科學系助理教授陳杰提到,若把上述兩款模型結合使用,就像同時具備Sora及傳統動畫製作的優勢。

MotionGPT及BuVatar配搭使用
陳杰指出,傳統動畫電影兼顧每項細節,卻要動用大量動畫師;現時大熱的Sora模型,可根據指令生成連貫影片,惟較難精準編輯內容。至於MotionGPT及BuVatar,使用上可謂相輔相成。MotionGPT專注動作生成,BuVatar可用於創作虛擬角色。以前者驅動後者,或能為影視業及相關學系學生,提供一種低預算的製片解決方案。
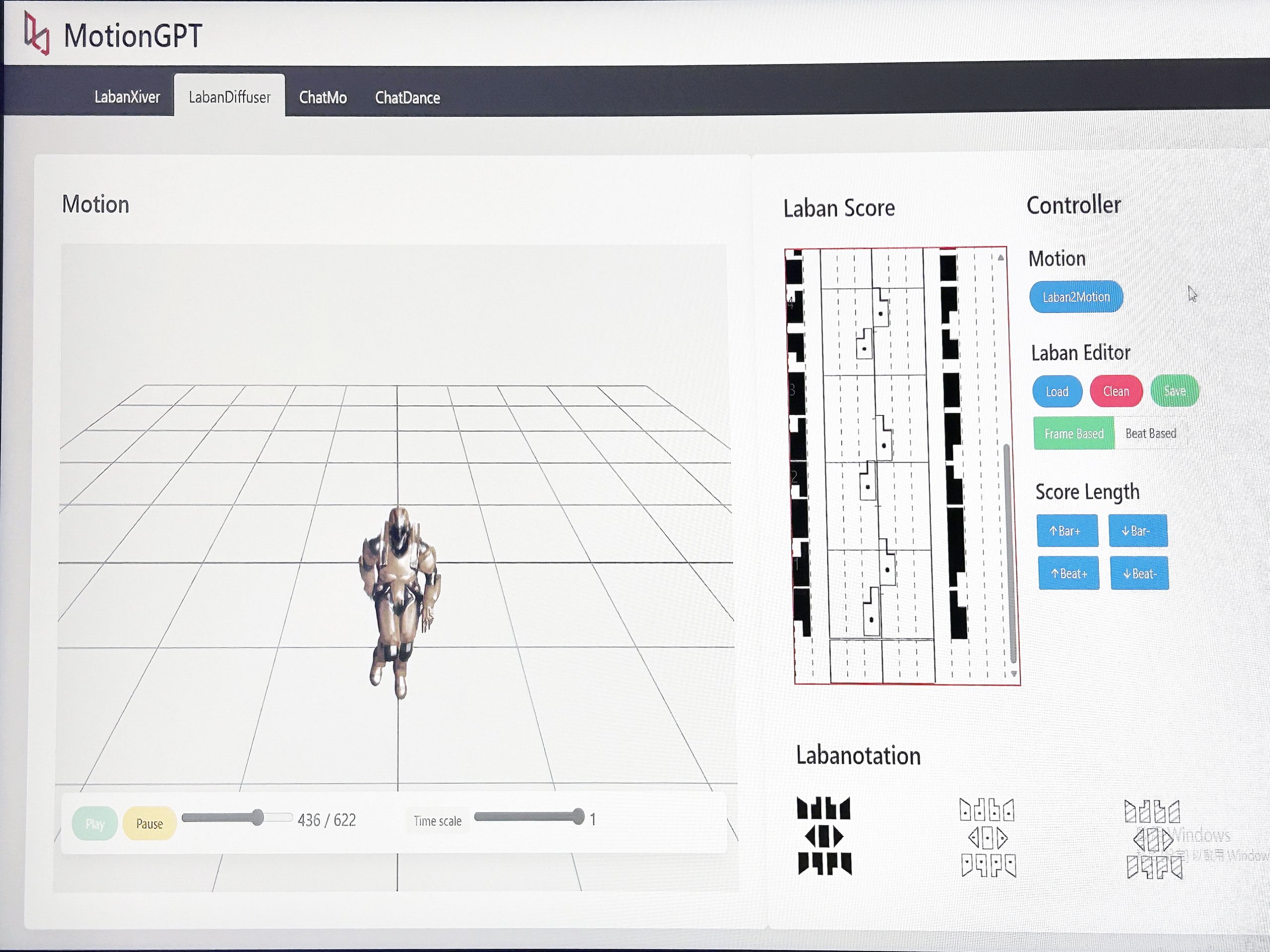
採拉班舞譜助LLM理解
人類運動時姿勢極為複雜,陳杰表示,這正是MotionGPT採用「拉班舞譜」(Labanotation)這一動作統計方式的原因。「拉班舞譜」歷史悠久,當中涉及解剖學、數學及力學等多種科學理論知識,用符號精確記錄人體的運動姿態、空間關係、動作節奏,甚至所用力量。
陳杰續解釋,把動作編排成符號,相當於字典的一個個字詞,大型語言模型(LLM)可透過這本「字典」,理解用戶想生成的動作。此外,MotionGPT亦能分析用戶所提供的音樂,讓三維模型隨意發揮(Freestyle)一段風格相近的舞蹈。
至於BuVatar的亮點,在於透過自然語言及視覺引導(Visual Prompts),例如提供一張類似效果的相片。可為MotionGPT生成的粗糙模型,添上生動細緻的外觀。陳杰又說,傳統電腦圖學三維模型,採用光線追蹤方式,透過模擬光線在真實場景的折射、反射等生成模型,過程繁瑣且耗費大量算力資源。
頭髮衣物處理勝電腦繪圖
BuVatar基於擴散渲染引擎,不僅能根據用戶需求,穩定地生成高精度模型,其頭髮、衣物褶皺等處理能力,亦遠勝傳統電腦繪圖。談及兩款模型研發成本,陳杰透露人力資源佔比最多。一個模型大約要兩位博士學生,投入4年時間方能完成;團隊近期亦成立初創「影蹤藝術科技」,希望方案獲業界採用。

採訪、撰文:周泳彤
支持EJ Tech

 如欲投稿、報料,發布新聞稿或採訪通知,按這裏聯絡我們。
如欲投稿、報料,發布新聞稿或採訪通知,按這裏聯絡我們。















{kind=link}
{kind=link}