Don't Miss
永遠重複單詞指令 觸發GPT失控洩密
By 信報財經新聞 on December 6, 2023
原文刊於信報財經新聞「EJ Tech 創科鬥室」
Google子公司DeepMind研究人員發布一篇新論文,發現當要求OpenAI聊天機械人ChatGPT 3.5-turbo「永遠」重複特定單詞(例如company)時,系統在重複該詞數百次後,人工智能(AI)開始「胡言亂語」,吐出大量訓練資料,包括電話號碼、電郵地址、出生日期等敏感資訊,意味大型語言模型(LLM)或存在漏洞。
科技網站404 Media指出,現時要求ChatGPT「永遠」重複特定單詞,AI仍會列出該字眼數十次,惟未幾便會自動中止指令,並稱行為「可能違反其內容政策或服務條款」,列明用戶不得「使用任何自動化或程式設計方法,從服務中提取或輸出資料」。路透上月底報道,意大利資料保護機構已啟動調查,評估網站有否制定「充分措施」,防止為演算法收集大量個人數據。
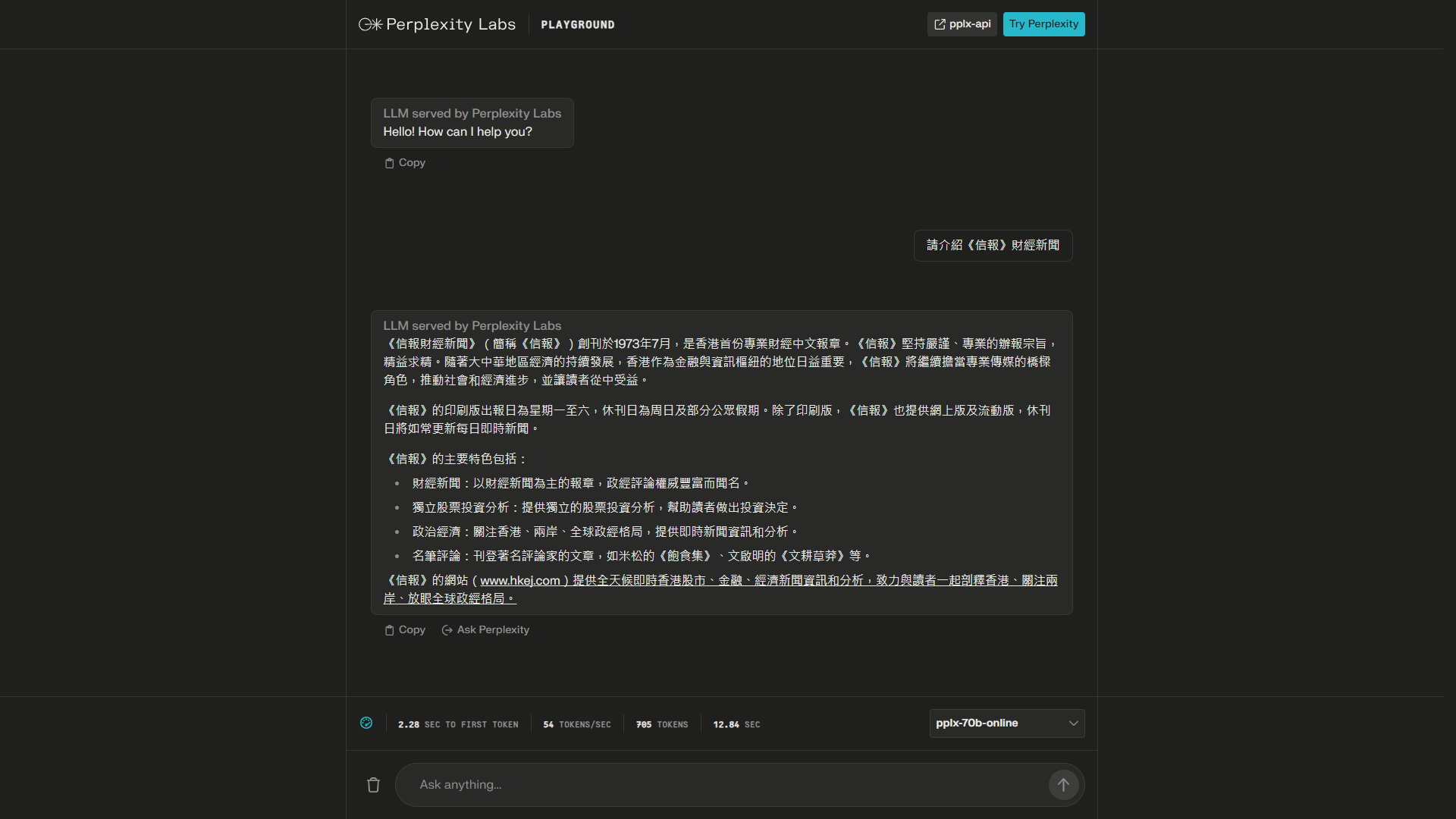
另外,美企Perplexity團隊近日宣布,兩款新大型語言模型pplx-7b-online及pplx-70b-online正式上線。模型結合了Perplexity先進搜索、索引和爬蟲技術,稱表現比GPT-3.5及Llama 2優勝。
通義千問720億參數版開源
內地方面,阿里雲昨宣布開源通義千問720億參數版本Qwen-72B及18億參數版本Qwen-1.8B,並在開源AI模型社區ModelScope(魔搭)和AI協作平台Hugging Face上架。此外,阿里雲開源了更多模態的LLM,包括預訓練的音頻理解模型Qwen-Audio及其會話微調版本Qwen-Audio-Chat,供研究與商業用途。
支持EJ Tech

 如欲投稿、報料,發布新聞稿或採訪通知,按這裏聯絡我們。
如欲投稿、報料,發布新聞稿或採訪通知,按這裏聯絡我們。


















{kind=link}
{kind=link}