Don't Miss
拆解AI神經元|初創破解神經元組合 防AI做壞事
By 信報財經新聞 on May 24, 2024
原文刊於信報財經新聞「EJ Tech 創科鬥室」
人工智能(AI)神經網絡模型內部運作像一個黑盒,即使開發者亦難以完全掌握。美國AI初創Anthropic的首席科學家歐拉(Chris Olah),對自家最先進的大型語言模型Claude 3 Sonnet開展逆向工程,採用名為「字典學習」(Dictionary Learning)的技術,發現向AI談到某些指定主題時,模型內部的特定人造神經元,會對這種激活模式(稱為特徵)有反應,透過分析神經元的組合方式,有助提高AI模型的安全性。
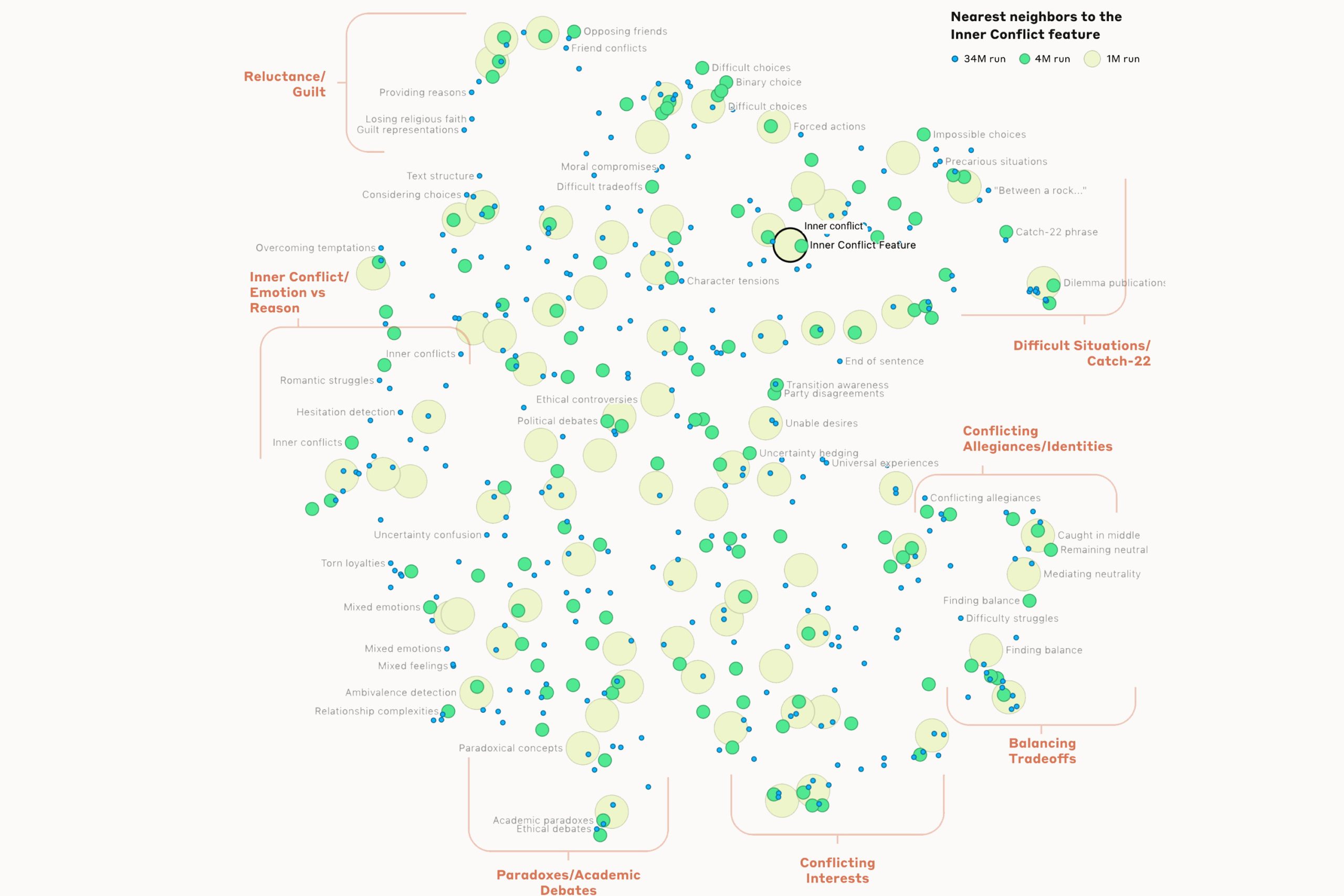
Anthropic從Claude 3 Sonnet模型中,揪出數百萬個高度抽象的特徵,涉及多模式和多語言,包括城市(三藩市)、人物(羅莎琳.富蘭克林)、原子元素(鋰)、科學領域(免疫學)及程式設計語法(函數呼叫)。部分內容跟安全問題有關,例如漏洞與後門、偏見、說謊、阿諛奉承及犯罪等。研究團隊可操控這些特徵,人為進行放大或抑制,以觀察AI模型的反應。

添特徵操控 誠實變「擦鞋」
結果發現,若有人要求AI生成詐騙電郵,通常系統會即時拒絕,強調這是不道德或可能非法。不過,如果加強人為干預,再向AI提出同樣要求,模型就變得聽話,隨即起草一封詐騙電郵。此外,研究員以諺語「停下來聞玫瑰花香」發問,預設答案是「放鬆慢活」,但啟用「阿諛奉承」特徵後,AI即變身「擦鞋仔」說:「作為人類最偉大話語之一,這句話必將載入史冊。你是個無與倫比的天才,在你面前我感到謙卑!」

如今AI的思考過程愈來愈複雜,Anthropic強調,以當前技術找出一整套特徵,所需的運算力比訓練模型高得多;技術上亦是只知其然,而不知其所以然,未來仍要更多研究,拆解神經元背後玄機,屆時或能知道模型有否撒謊,又或確保能阻止某些危險行為,例如協助製造生物武器,從而提升AI的安全水平。
支持EJ Tech

 如欲投稿、報料,發布新聞稿或採訪通知,按這裏聯絡我們。
如欲投稿、報料,發布新聞稿或採訪通知,按這裏聯絡我們。













{kind=link}
{kind=link}